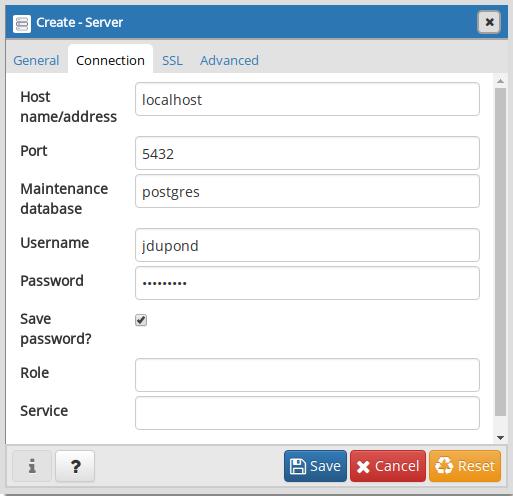
Postgres psql est un client en ligne de commande du serveur PostgreSQL. Il permet de se connecter au serveur de bases de données en local sur la machine serveur ou à distance depuis une autre machine. Une fois connecté, l’utilisateur autorisé peut exécuter des commandes spécifiques à psql qui retournent différentes informations utiles ou exécuter des requêtes SQL. A ce titre il constitue un outil léger et performant pouvant rendre de nombreux services au cours d’un développement qui utilise ce serveur de bases de données. Dans ce tutoriel le login de l’utilisateur authentifié sur la machine est supposé être jdupond. Pour exécuter les commandes des exemples, remplacer toujours ce login par le votre.
Cet article fait partie d’une série qui concerne le serveur de bases de données PostgreSQL et son utilisation dans un environnement de développement:
- Installation de base de PostgreSQL
- Utiliser Postgres pgAdmin 3 pour administrer PostgreSQL
- Installer PostgreSQL 10
- Reconfigurer l’installation par défaut de PostgreSQL 10
- Utiliser PostgreSQL 10 dans un environnement de développement
- Cet article: Administrer PostgreSQL avec psql
- Postgres pgAdmin 4 : installation et configuration
- Postgres pgAdmin 4: Utilisation courante
1. Connexion au serveur de BDD avec Postgres psql
La commande de connexion est de la forme suivante:
psql -h <AdresseServeur> -p <Port> -U <UtilisateurBDD> -d <BaseDeDonnees>
Aucun des 4 paramètres n’est obligatoire. Quand l’un de ces paramètres n’est pas fourni, sa valeur par défaut est prise en compte:
| Paramètre |
Contenu |
Valeur par défaut |
| h |
Adresse de la machine serveur de base de données |
Connexion en local par le socket Unix |
| p |
Port de connexion sur la machine serveur |
5432 |
| U |
Utilisateur de base de données |
login de l’utilisateur qui exécute la commande |
| d |
Base de données |
login de l’utilisateur qui exécute la commande |
A titre de test, exécuter:
psql
La commande échoue, le message d’erreur indique qu’il n’y a pas de BDD qui a pour nom le login. Si on exécute:
psql -d postgres
La connexion réussit dans le cas d’un cluster personnalisé pour l’utilisateur authentifié.
Pour se connecter en tant que
utappli sur la BDD
bdappli:
psql -h localhost -U utappli -d bdappli
La commande demande le mot de passe car
utappli est soumis à ce type d’authentification, puis réussit.
2. Postgres psql peut se souvenir de la BDD par défaut et des mots de passe
Il existe deux paramétrages possibles qui permettent de simplifier la commande de connexion.
- Modifier la BDD à utiliser par défaut.
Pour cela créer le fichier
.postgresqlrc comme suit:
vi /home/jdupond/.postgresqlrc
Son contenu doit être:
10 pgtest bdappli
Exécuter après avoir enregistré:
psql
La connexion réussit. La BDD à laquelle on se connecte est
bdappli qui remplace, par défaut, le login de l’utilisateur.
- Se souvenir du mot de passe de l’utilisateur de connexion
Pour se connecter en tant que
utappli, psql demande de saisir le mot de passe à chaque fois. Ce comportement peut être modifié en renseignant le mot de passe dans le fichier
/home/jdupond/.pgpass
Créer ce fichier avec le contenu (
mputappli est le mot de passe de
utappli):
localhost:5432:*:utappli:mputappli
Ce nouveau fichier contenant un mot de passe, il faut le sécuriser:
chmod 600 /home/jdupond/.pgpass
Exécuter ensuite:
psql -h localhost -U utappli -d bdappli
La connexion réussit sans demander le mot de passe de l’utilisateur.
3. Utiliser les commandes de Postgres psql
En plus de la capacité d’exécuter des requêtes SQL, l’utilitaire
psql fournit un ensemble de commandes utiles pour l’exploitation du serveur.
Etant connecté au serveur PostgreSQL, à la base de données
bdappli, avec l’utilitaire
psql, on va tester un certain nombre de ces commandes. Exécuter l’une de ces commandes revient à la saisir et ensuite utiliser la touche entrée du clavier.
\?
Permet d’afficher la liste complète des commandes
psql avec une description de leurs fonctions. Remarquer que ces commandes commencent
toujours par le caractère backslash (
\).
\h select
Fournit une explication complète de la syntaxe de la commande SQL
select. La commande psql
\h est un aide mémoire précieux du langage SQL.
\l
Affiche la liste des bases de données du serveur.
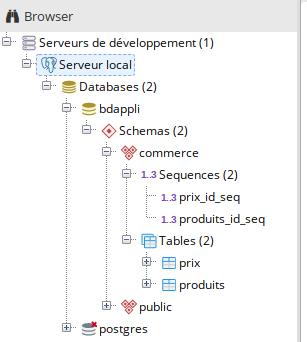
\dn
Permet de voir la liste des schémas de la base de données
active.
\d commerce.*
Affiche les informations à propos de toutes les tables du schéma
commerce. Remarquer la table créée automatiquement pour gérer la séquence du champ
id
\d commerce.produits
Affiche les informations à propos de la table
produits du schéma
commerce.
4. Echanger les données avec des fichiers grâce à Postgres psql
Créer le fichier
/home/jdupond/produits.csv avec le contenu:
CU;clé usb 500 Go
EC;ecran 26 pouces
SR;souris 3 boutons
CA;clavier azerty
Se connecter à la base de données
bdappli et exécuter les deux requêtes l’une après l’autre:
copy commerce.produits(code,nom) from '/home/jdupond/produits.csv' (format csv, delimiter ';', header, encoding 'utf8');
select * from commerce.produits;
Comme le montre le résultat de la deuxième requête, le contenu du fichier a été transféré dans la table de la base de données.
Exécuter maintenant:
copy commerce.produits to '/home/jdupond/extraction_produits.csv' (format csv, delimiter ';', header, encoding 'utf8');
Le contenu
entier de la table est transféré dans le fichier indiqué et au format indiqué.
Le contenu transféré peut être
partiel, selon une condition, en utilisant une requête SQL:
copy (select * from commerce.produits where id=1 or id=2) to '/home/ameddeb/dvlp/travaux/pgdoc/extractionl_produits.csv' (format csv, delimiter ';', header, encoding 'utf8');
Seulement les deux enregistrements demandés ont été transférés.
5. Exécuter une requête SQL depuis le shell système
Postgres psql permet d’exécuter une requête SQL sans se connecter préalablement au serveur. Depuis le shell, exécuter:
psql -c "select * from commerce.produit;"
Le résultat est affiché sur la console.
6. Exécuter un script SQL depuis un fichier
Créeer le fichier
/home/jdupond/cree_prix.sql avec le contenu:
create table commerce.prix(id serial, produitid int, prixachat numeric(7,2), prixvente numeric(7,2));
insert into commerce.prix(produitid, prixachat, prixvente) values(1, 6.2, 7.35);
insert into commerce.prix(produitid, prixachat, prixvente) values(2, 230.5, 274.75);
Ensuite exécuter depuis le shell système:
psql -f /home/jdupond/cree_prix.sql
psql -c "select * from commerce.prix;"
Le script s’exécute, crée la table et y insère deux enregistrements. Le résultat de la requête exécutée après le script le confirme.]]>